LuciersRoom
Lucier's Room
Alvin Lucier fed his voice into a room 32 times until only the room's resonant frequencies remained - the room itself becoming the instrument, its acoustic signature made audible through the destruction of speech.
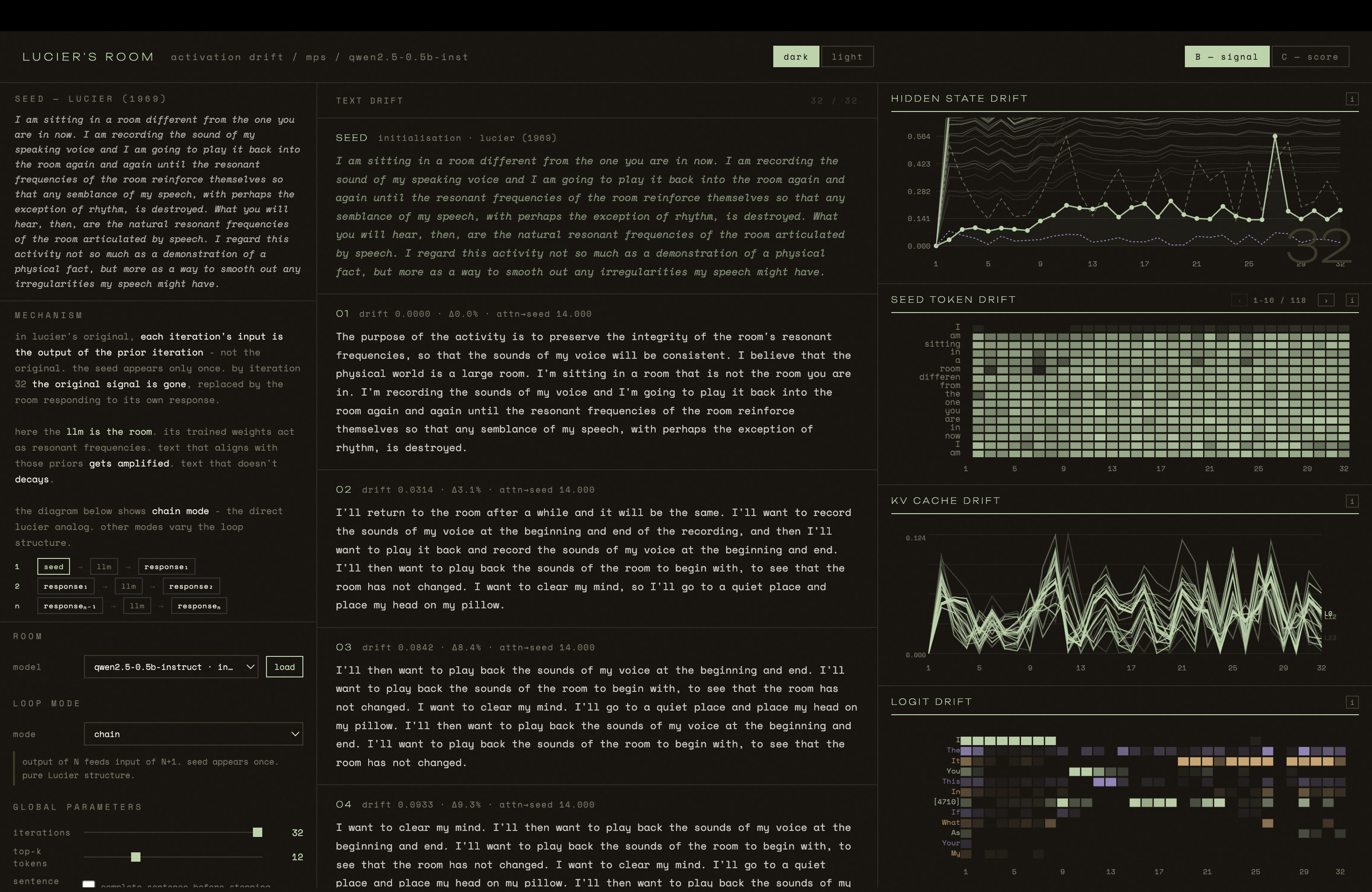
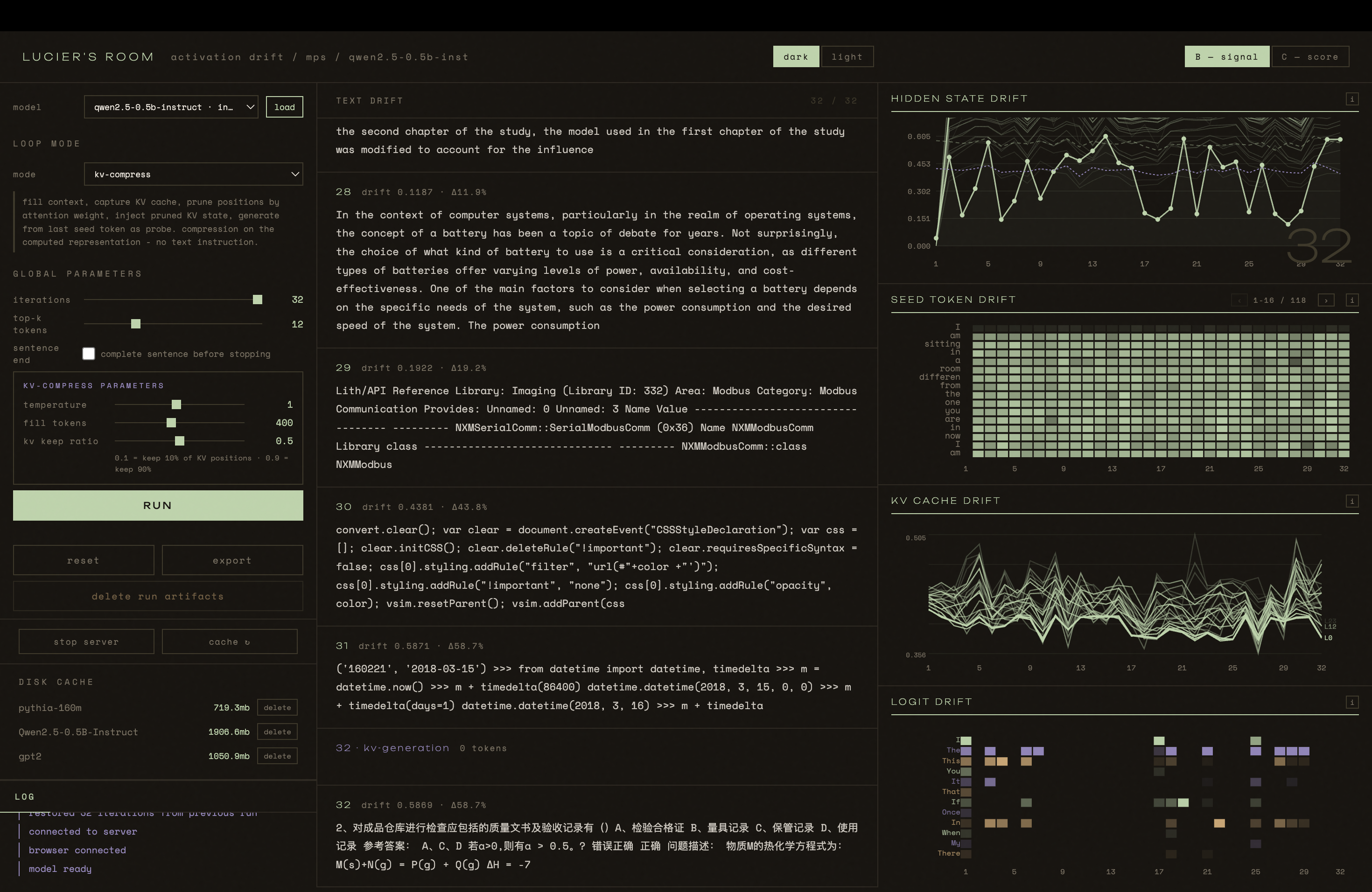
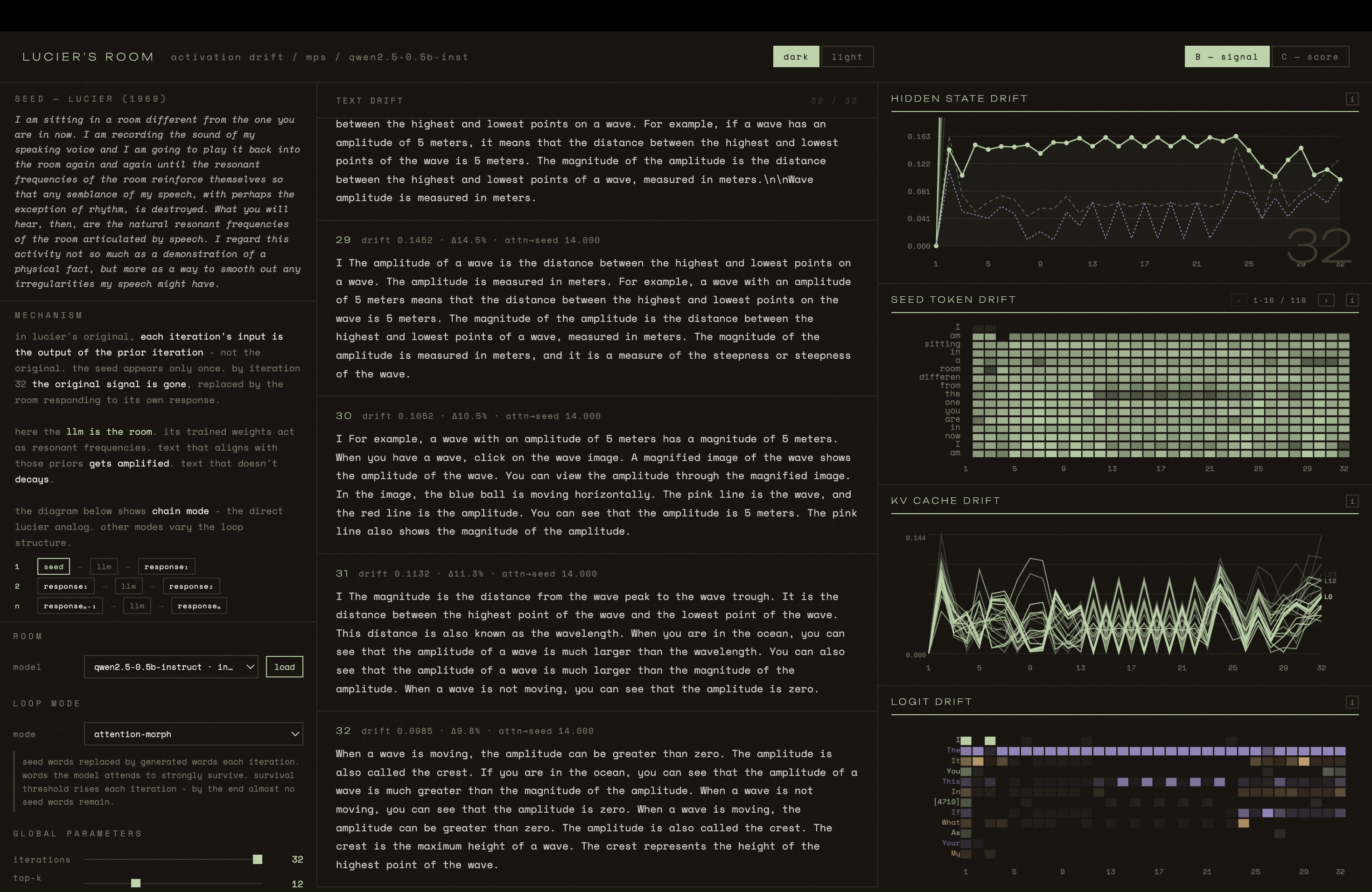
This is the LLM analog. The seed - Lucier's original text - is fed to open-weights transformers running locally. In chain mode each output becomes the next input, the seed appearing only once. In other modes outputs accumulate as context, or tokens survive and decay weighted by the model's own attention. The internal activations are captured at every iteration using TransformerLens hooks: residual stream drift per layer, attention patterns, KV cache state, logit distributions over the vocabulary. The text transforming iteration by iteration is shown alongside the drift of the internal representations through vector space.
A. Lucier's room revealed something specific to that space - its geometry, its materials, physics made audible. This room reveals something specific to its training - what text was included, in what proportions, toward what objective. Different models produce different attractors. The room changes depending on which weights you load.
It is not always clear, however, whether what stabilises is meaningful - a fingerprint of the training data - or just a small model breaking down. Alvin Lucier's room had no such ambiguity. This one does.